Research
[Theme 1] Learning Robust Optimal Policy from Strongly Correlated and Corrupted Observations
Can reinforcement learning still discover an optimal policy when the feedback it receives is both statistically dependent and adversarially corrupted? This line of work answers this question by developing a finite-time theory for robust optimal policy learning from unreliable trajectories, where rewards, transitions, observations, or Bellman targets may be strategically distorted. We show that standard algorithms such as vanilla Q-Learning can be fundamentally brittle under even small corruptions, and then design robust Bellman-update schemes that recover near-clean statistical performance up to an explicit and unavoidable corruption penalty. Together, this series of work, appearing across major venues including ICML 2026, IEEE CDC 24, CDC 26, and the NeuRIPS 2025-Reliable ML Workshop, establishes some of the first fundamental guarantees for learning optimal policies from strongly correlated and corrupted observations, combining robust statistics, stochastic approximation, and Bellman fixed-point theory to identify both what is algorithmically achievable and what is information-theoretically impossible.
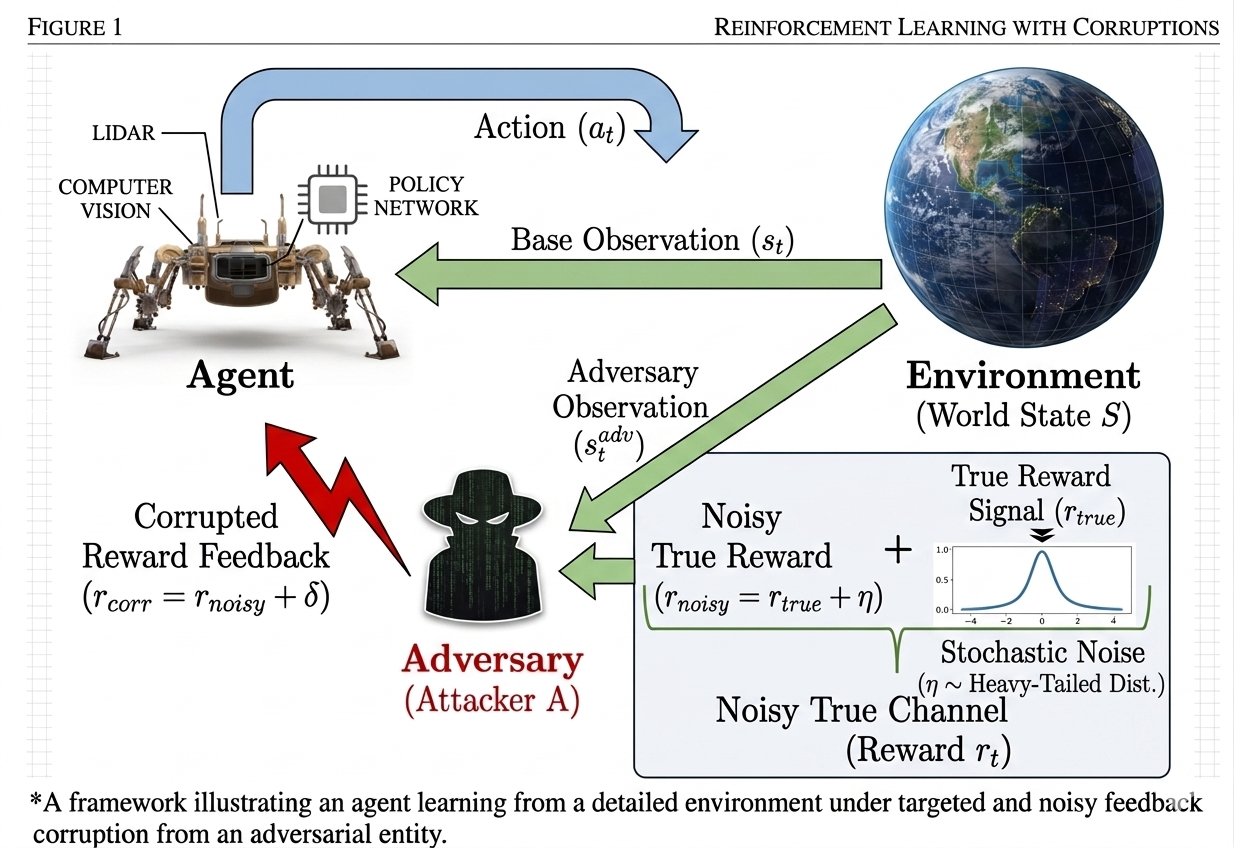
Recently, there has been a surge of interest in understanding the non-asymptotic behavior of model-free reinforcement learning algorithms. However, the performance of these algorithms in non-ideal environments, particularly under corrupted rewards, remains poorly understood. Motivated by this gap, we study the robustness of the celebrated Q-Learning algorithm under a strong-contamination attack model, where an adversary can arbitrarily perturb a small fraction of the observed rewards. We first show that such attacks can cause vanilla Q-Learning to incur arbitrarily large errors.
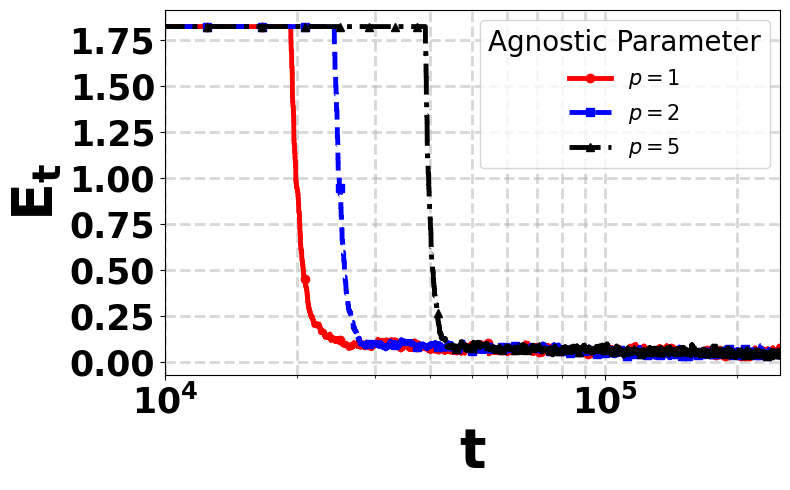
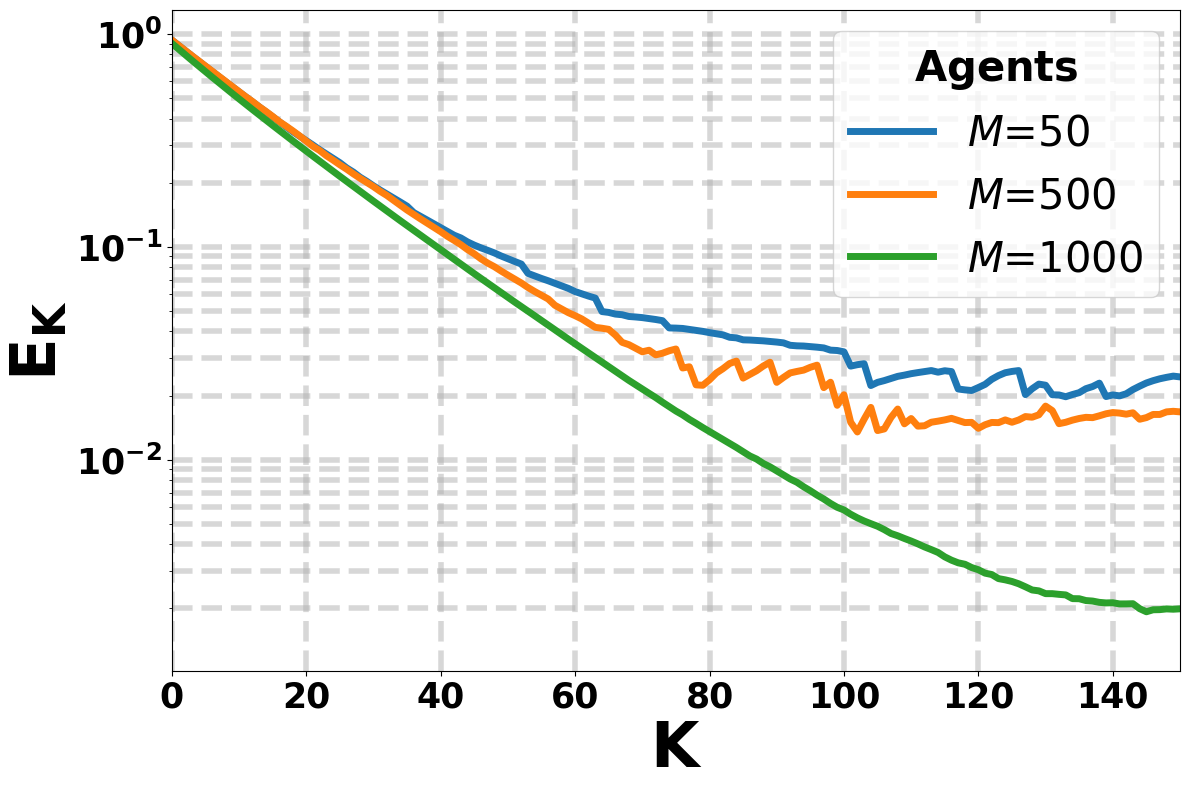
We then develop robust \(Q\)-Learning algorithms that use historical reward data to construct robust empirical Bellman operators. Our first variant is reward-statistics aware and leverages distributional information, such as reward scale, to obtain sharp finite-time guarantees. We then develop a reward-statistics agnostic version that does not require prior knowledge of the true reward distribution, using an agnostic tuning parameter \(\color{#fca5a5}{p}>1\) to control the robustness–concentration tradeoff. For both i.i.d. (\(\bar{\tau}_{\mathrm{mix}}=1\)) and Markovian data, both approaches achieve finite-time convergence rates that match known state-of-the-art bounds up to a small and inevitable corruption-dependent term, which scales with the adversarial corruption fraction.
.png)
.png)
.png)
.png)
Representative Publications
[\(C_1\)] Corruption-Tolerant Asynchronous Q-Learning with Near-Optimal Rates (ICML 2026) [Paper]
[\(C_2\)] Robust Asynchronous Q-Learning under Reward and State Corruption via Batching (CDC 2026) [Paper]
[\(C_3\)] Robust Q-Learning under Corrupted Rewards (CDC 2024) [Paper]
[\(W_1\)] Agnostic Q-Learning under Corrupted Feedback (NeuRIPS 2025-Reliable ML Workshop)
[Theme 2] Robust Policy Evaluation and Temporal-Difference (TD) Learning
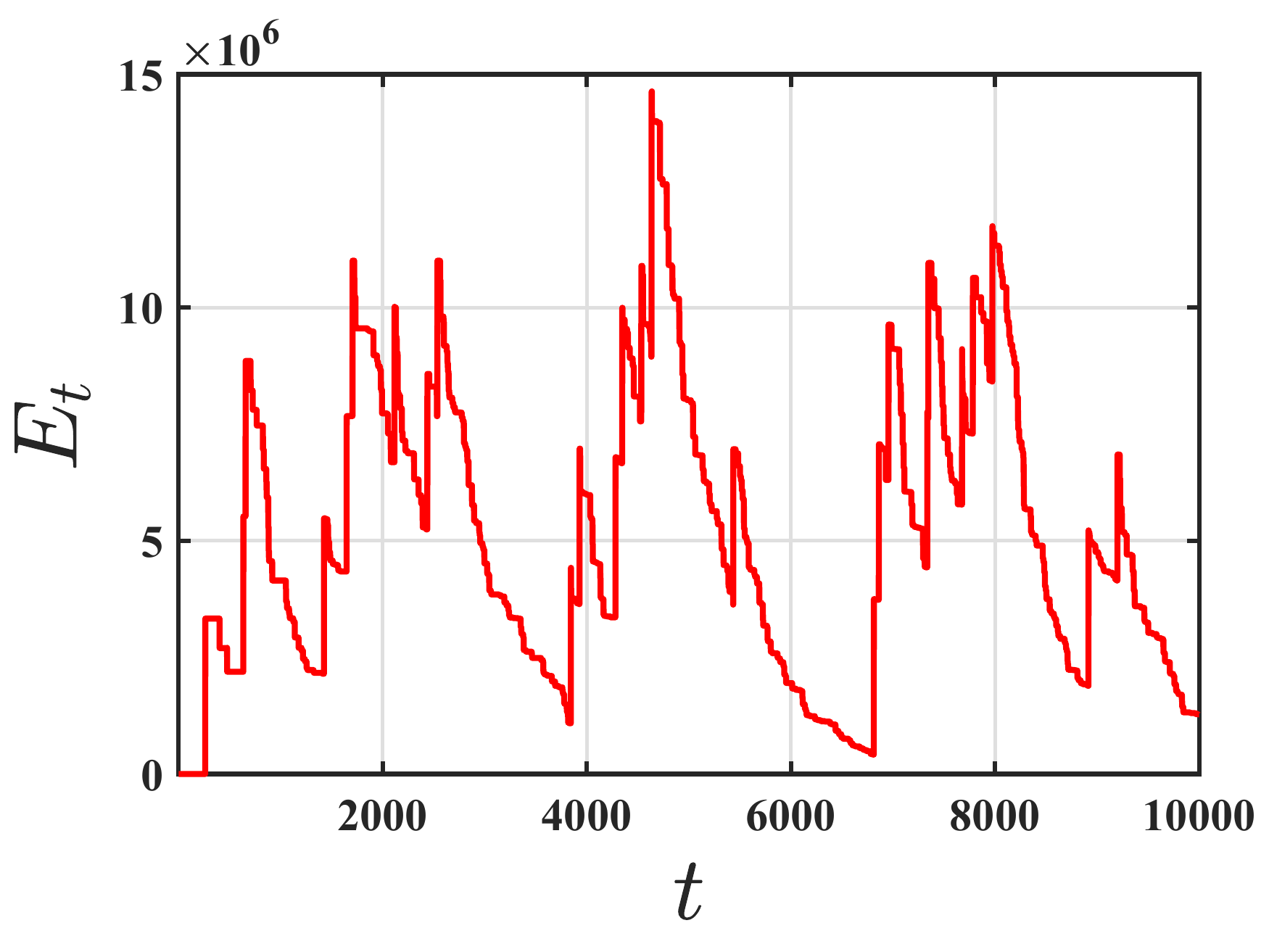
The second direction of my research focuses on robust policy evaluation with Markovian data and function approximation. In contrast to idealized i.i.d. sampling models, reinforcement learning data are often collected from a single trajectory, making consecutive observations strongly dependent. This temporal dependence makes robust estimation substantially more delicate, since the learner must distinguish genuine statistical fluctuations from adversarial perturbations while tracking the value function. In this line of work, which appeared at AISTATS 2025, we develop finite-time guarantees for robust temporal-difference learning under adversarial corruption and Markovian sampling, and clarify both what robust TD algorithms can achieve and what limitations are unavoidable under time-correlated corrupted data.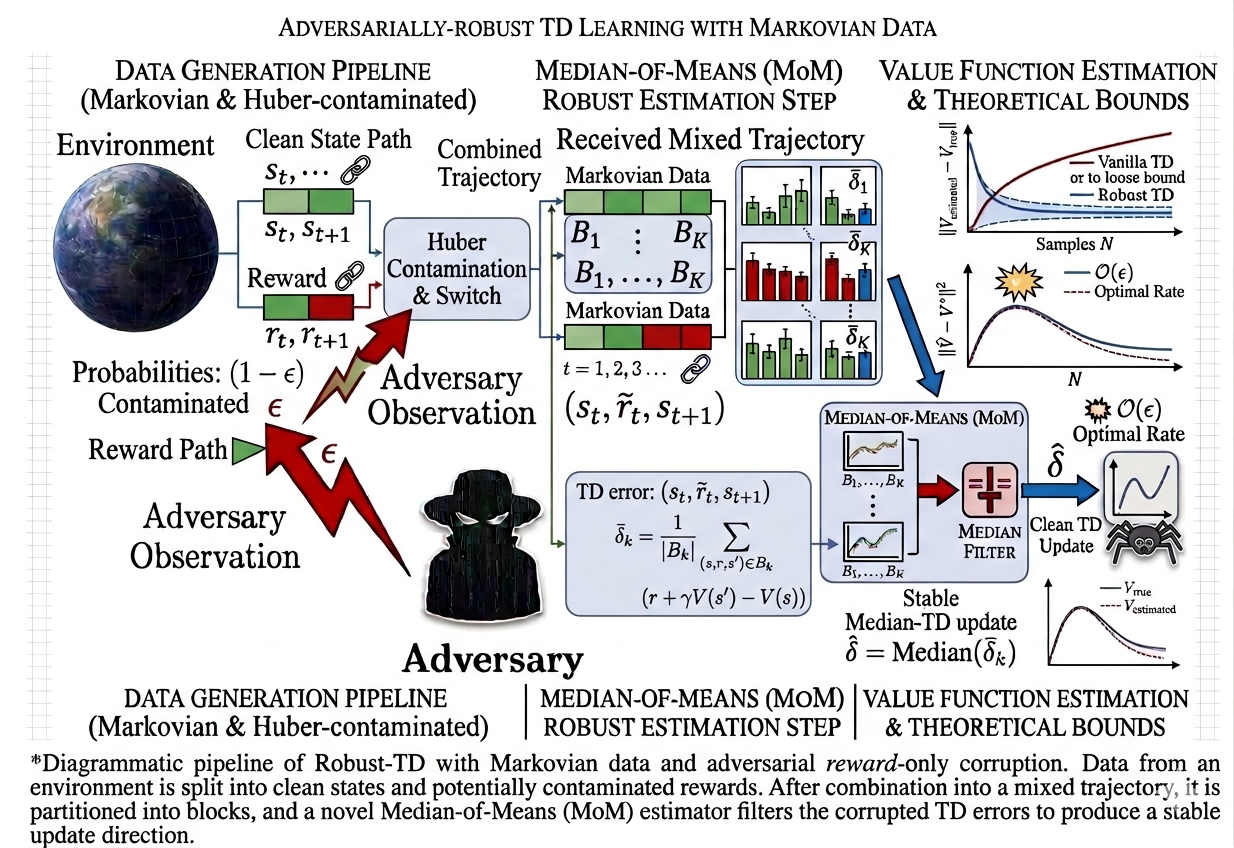
One of the fundamental challenges in reinforcement learning (RL) is policy evaluation, which involves estimating the value function—the long-term return—associated with a fixed policy. The well-known Temporal Difference (TD) learning algorithm addresses this problem, and recent research has provided finite-time convergence guarantees for TD and its variants. However, these guarantees typically rely on the assumption that reward observations are generated from a well-behaved (e.g., sub-Gaussian) true reward distribution.
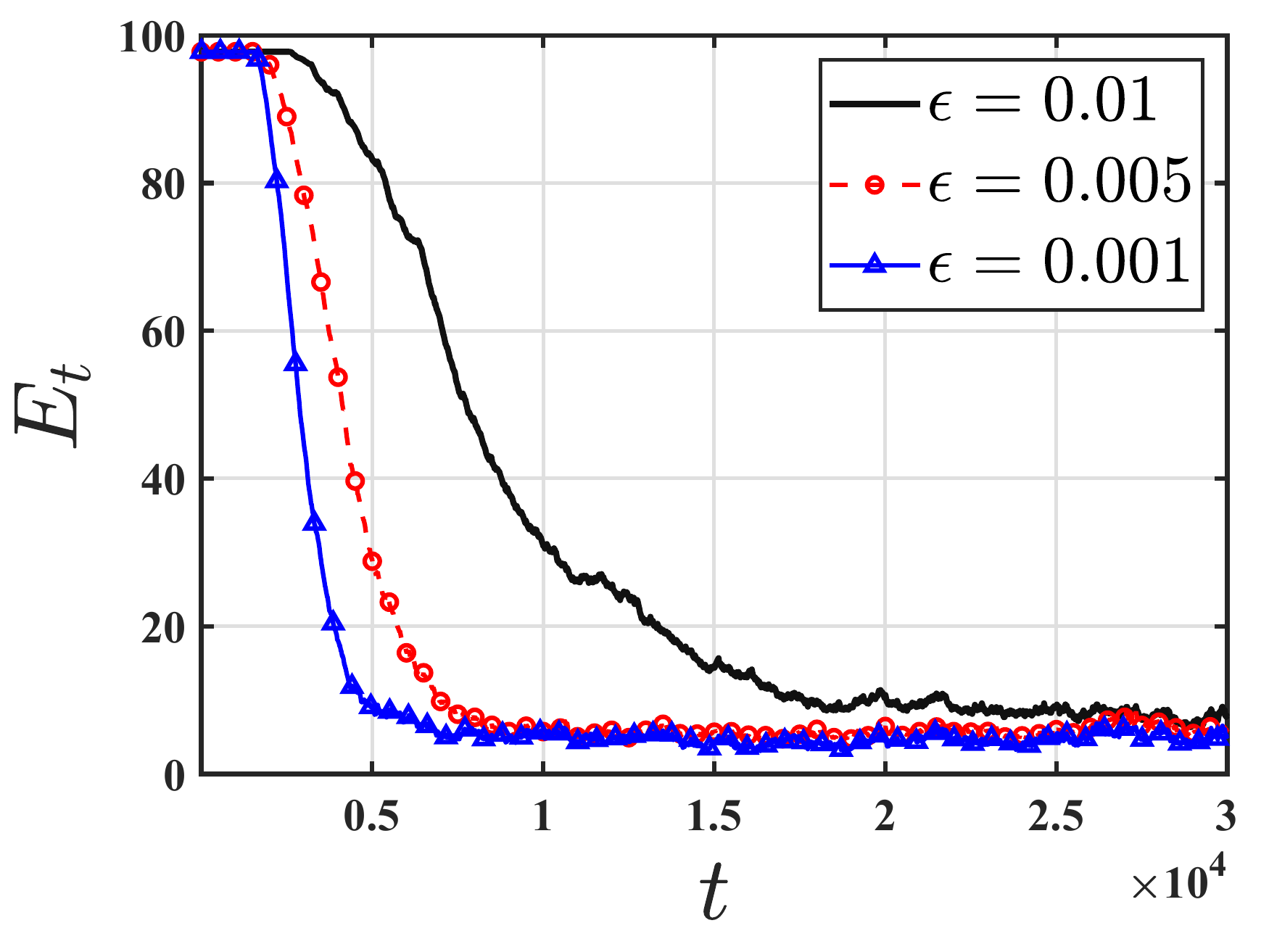
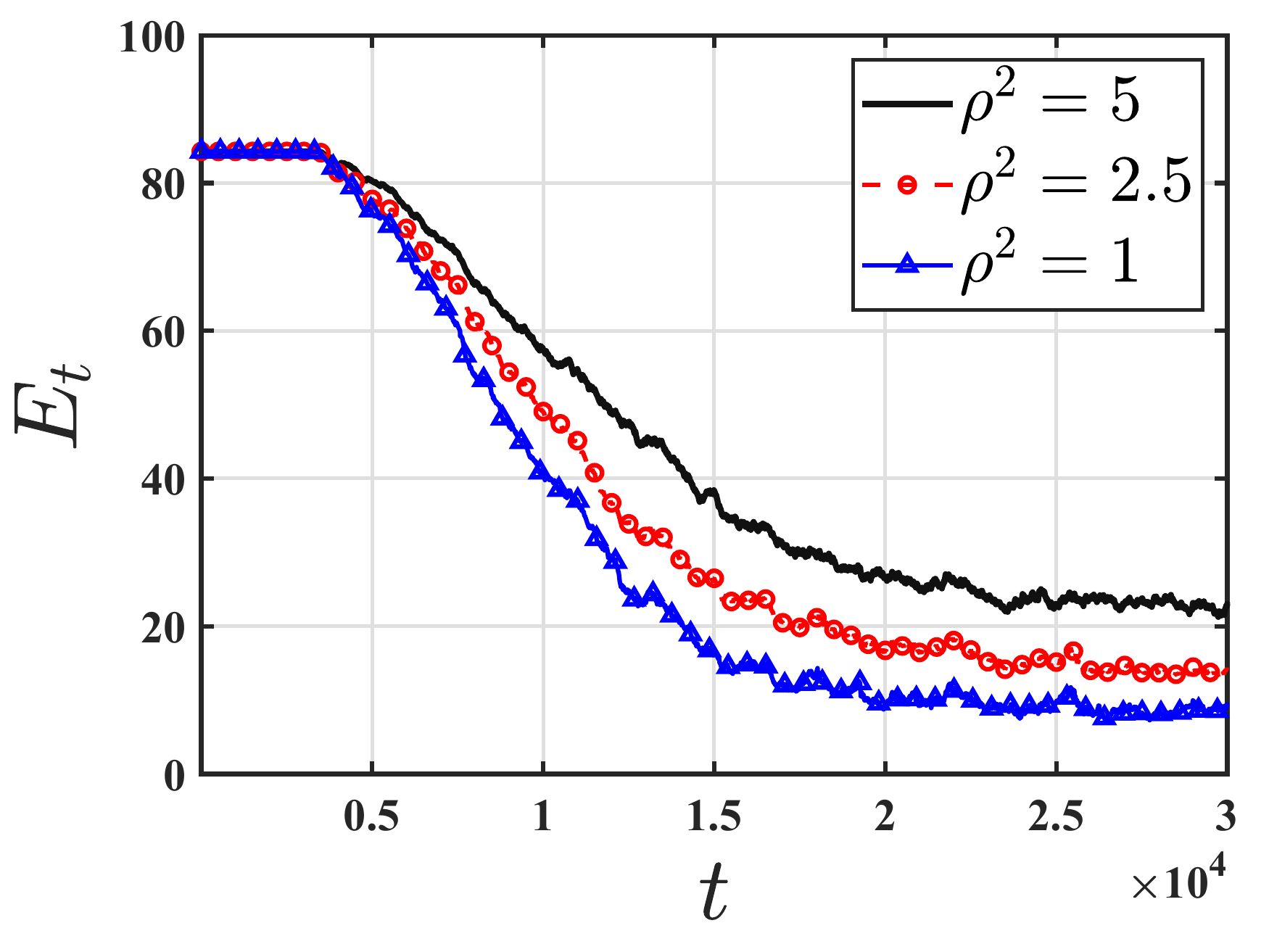
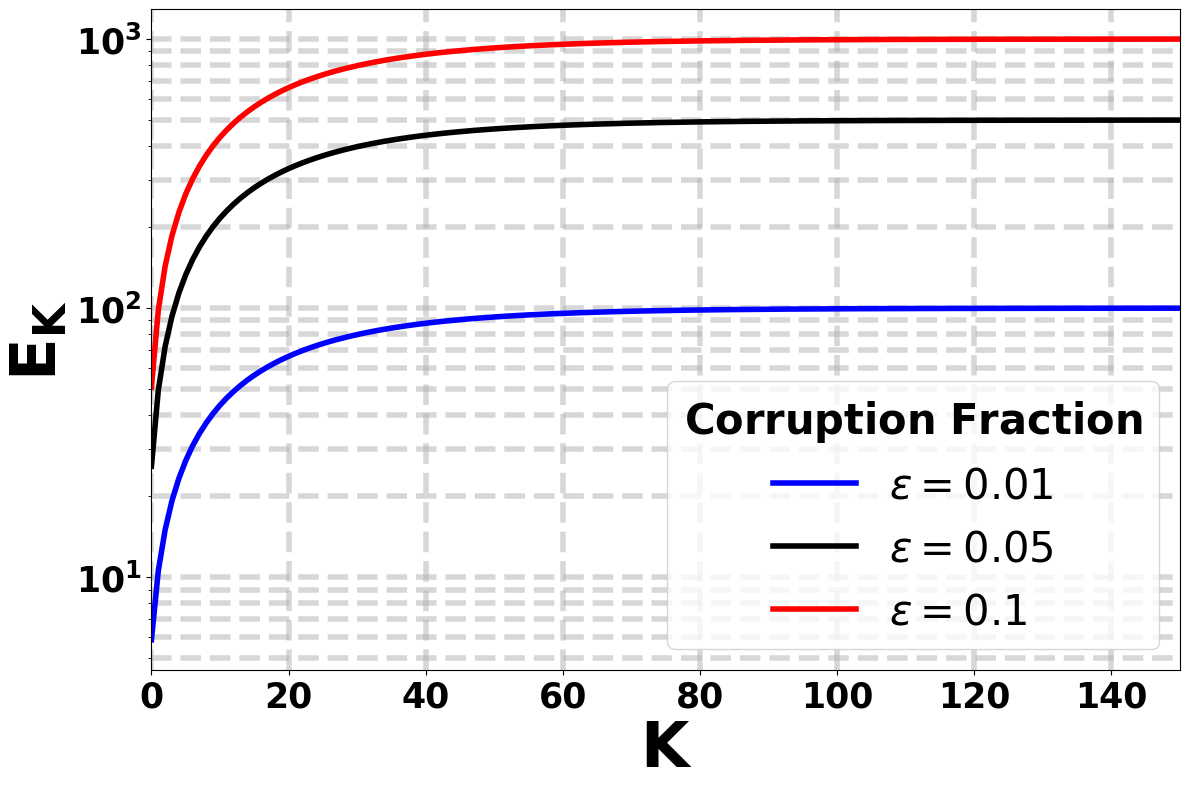
Recognizing that such assumptions may not hold in harsh, real-world environments, we revisit the policy evaluation problem through the lens of adversarial robustness. We develop a robust temporal-difference learning method and prove that, with linear function approximation, its finite-time guarantees match those of Vanilla-TD up to a small \(O(\varepsilon)\) term that precisely captures the effect of adversarial corruption.
\begin{equation} \inf_{\hat{V}_T} \sup_{V \in \mathcal{M}(\epsilon, \rho, \mathcal{Q})} \mathbb{P}\left( \Vert \hat{V}_T - V \Vert_2 \geq \frac{\tilde{c} \rho \sqrt{\varepsilon}}{(1-\gamma)}\right) \geq \frac{1}{2}. \end{equation}
Our lower bound shows that no algorithm can completely remove the effect of adversarial corruption: even the best possible method must incur an additive error proportional to the corruption level. Thus, the corruption-dependent term in our upper bound is not a proof artifact, but a fundamental statistical barrier. To our knowledge, these results are the first of their kind in the context of adversarial robustness of stochastic approximation schemes driven by Markov noise.
Representative Publications
[\(C_4\)] Adversarially-Robust TD-Learning with Markovian Data (AISTATS 2025) [Paper]
[Theme 3] Robust Federated Multi-Agent Reinforcement Learning
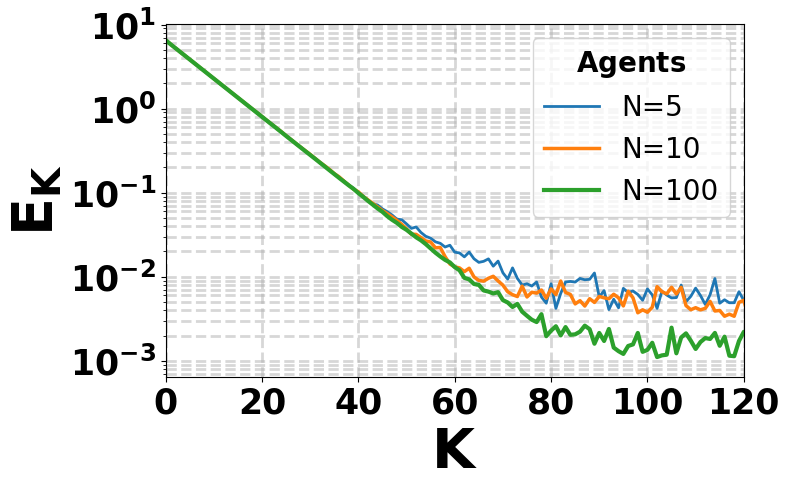
The third direction of my research focuses on robust federated reinforcement learning with Byzantine agents and minimal communication. In this setting, multiple agents interact with a common environment and send information to a central learner, but a fraction of the agents may be adversarial and can transmit arbitrary, corrupted messages. This creates a challenging tension between collaboration, robustness, and communication efficiency: the learner should benefit from distributed data collection while remaining resilient to malicious agents and avoiding excessive communication. In this line of work, which appeared at ACC 2026, we develop robust federated Q-Learning algorithms that achieve near-optimal finite-time guarantees with Byzantine tolerance and almost no communication, showing that collaborative speedups are still possible even when some agents are unreliable.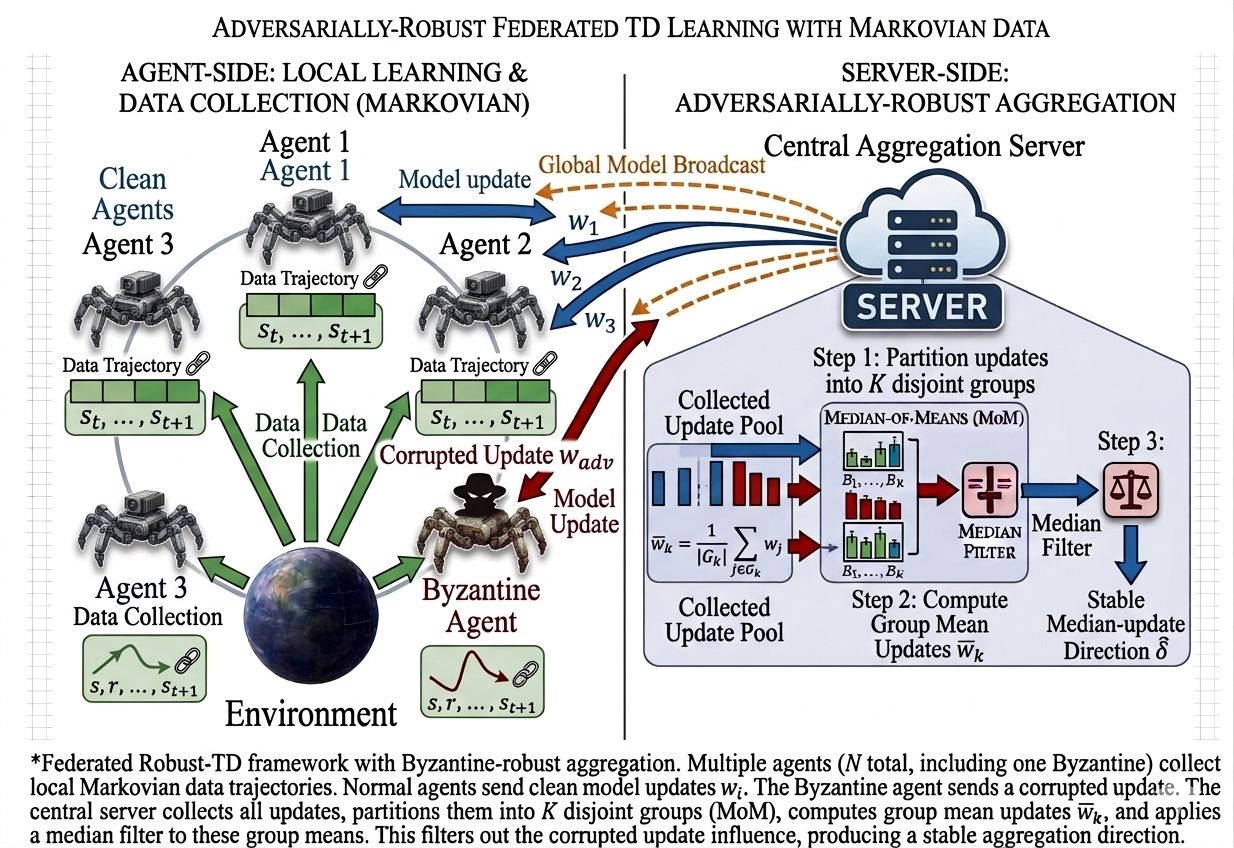
We consider a federated reinforcement learning setting with multiple agents interacting with a common Markov Decision Process, while communicating through a central server to learn the optimal value function. The central question is whether one can still obtain collaborative sample-complexity gains when a small fraction of agents are Byzantine and may send arbitrary, corrupted messages. To address this, we propose a novel federated \(Q\)-Learning algorithm that blends model-based and model-free reinforcement learning with median-of-means aggregation from robust statistics.
We prove that, with high probability, our proposed algorithm converges exactly to the optimal value function in the infinite-sample limit despite adversarial agents, and achieves near-optimal finite-time rates that retain the benefits of collaboration. More precisely, our finite-time bound takes the simplified form
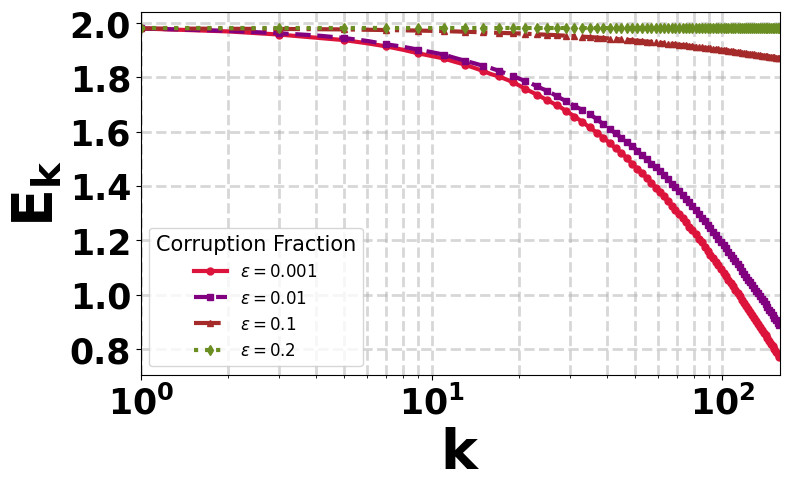
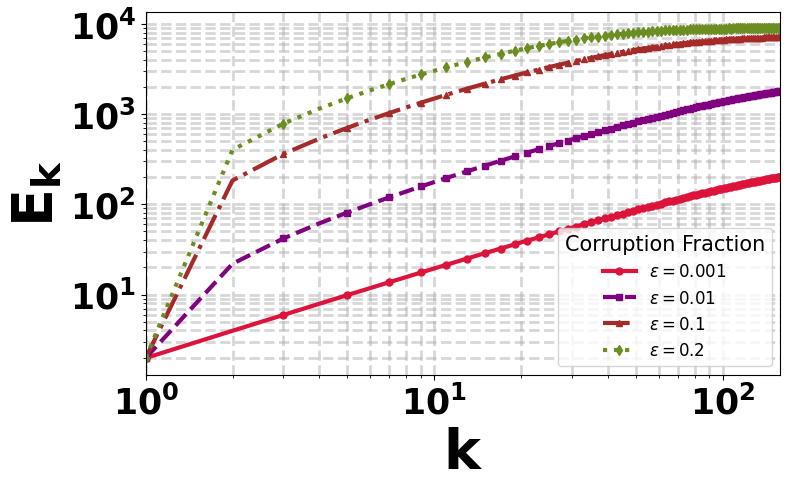
More precisely, our finite-time bound takes the simplified form \begin{equation} \|Q_K-Q^\star\|_\infty \;\le\; \widetilde{\mathcal O}\!\left(\frac{1}{\sqrt{MT}}\right) \;+\; \widetilde{\mathcal O}\!\left(\frac{\sqrt{\color{#fca5a5}{\varepsilon}}}{\sqrt{T}}\right). \end{equation} Here, \(M\) denotes the number of agents and drives the collaborative speedup, improving the clean statistical error from the single-agent rate \(1/\sqrt{\color{}{T}}\) to \(1/\sqrt{MT}\). The term involving \(\varepsilon\) captures the price of adversarial corruption; importantly, for any fixed corruption level, this term still decays with the number of samples \(T\), showing a vanishing corruption effect as learning progresses. Apart from that, these guarantees require only a constant number of communication rounds \(\widetilde{O}(1)\), making the method particularly appealing in federated learning settings where communication is often the dominant bottleneck.
.png)
[Theme 3-a] Decentralized and Networked Reinforcement Learning
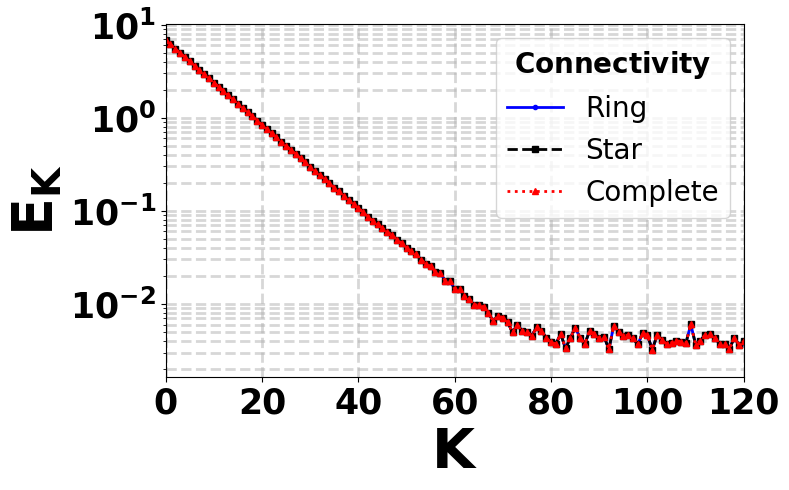
A second direction of my research focuses on decentralized reinforcement learning over general communication networks. Unlike centralized or server-based federated learning, here agents collaborate only through local message passing over an underlying graph. This setting raises a rich set of questions at the interface of reinforcement learning, distributed optimization, and networked systems: how does the network topology affect learning speed? How many rounds of consensus are needed to realize collaborative gains? How do local sampling noise and network-induced mixing errors interact? My goal is to develop algorithms and finite-time analyses that make these tradeoffs explicit.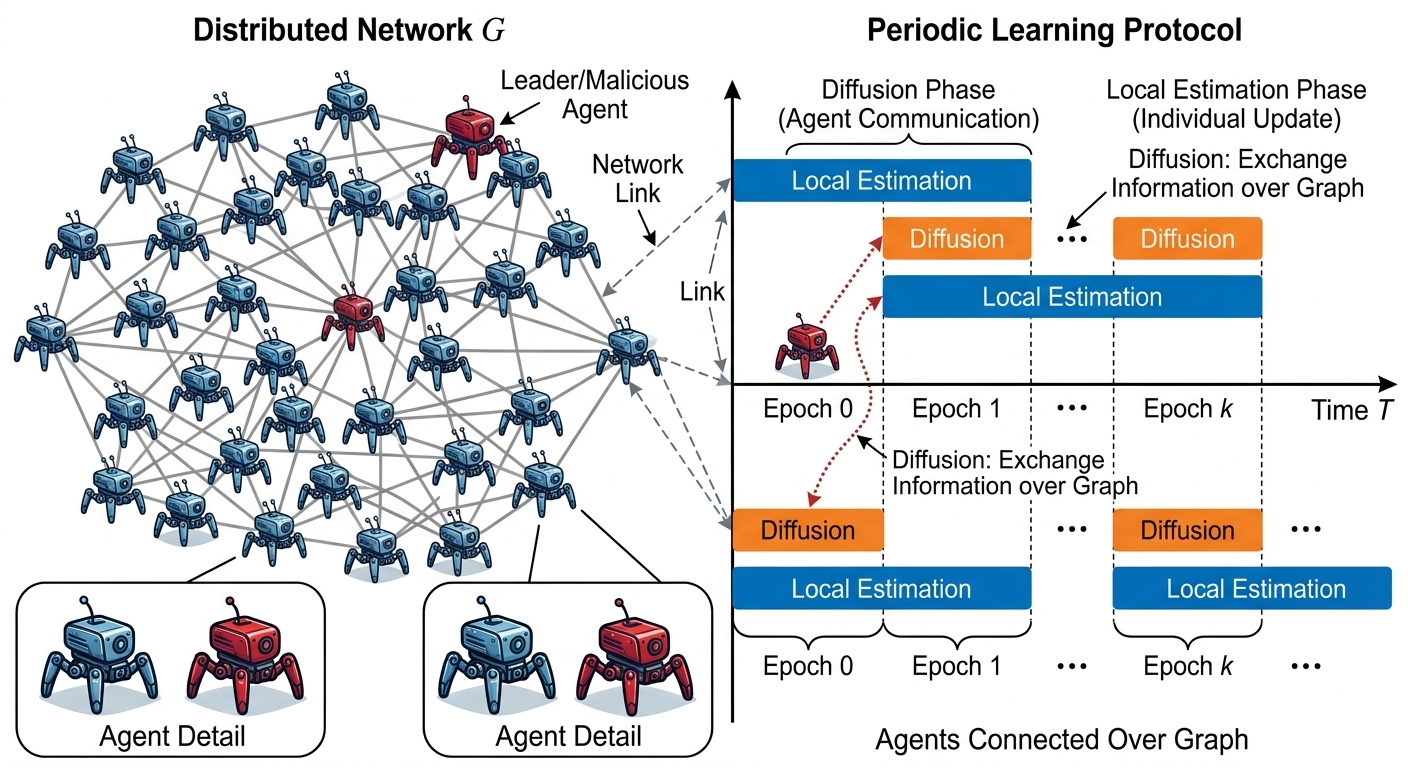
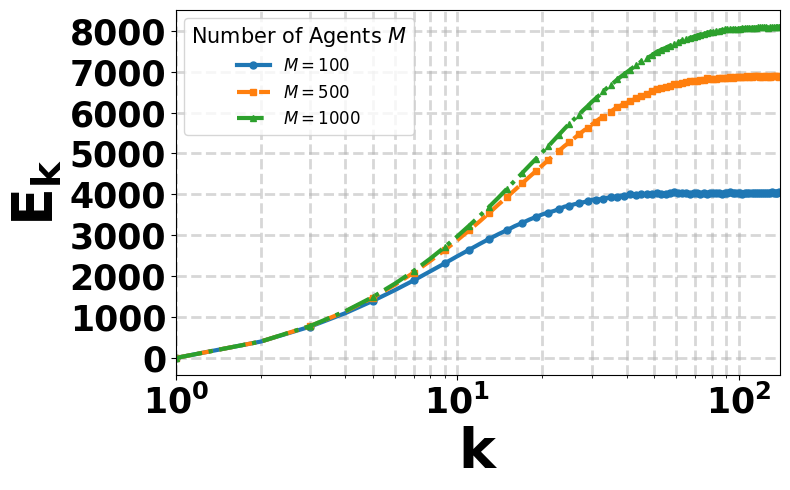
We consider a networked reinforcement learning setting in which multiple agents interact with a common Markov Decision Process and exchange information over a communication graph to collaboratively learn the optimal state-action value function. The central question is whether agents can achieve collaborative sample-complexity gains while incurring only limited communication overhead. To address this
question, we propose a novel epoch-based distributed \(Q\)-Learning algorithm that combines local Bellman operator estimation with consensus-based information diffusion. This design blends model-based variance reduction with model-free \(Q\)-function updates, enabling agents to attain the statistical benefits of collaboration with substantially reduced communication.
Representative Publications
[\(C_5\)] Robust Federated Q-Learning with Almost No Communication (ACC 2026) [Paper]
[\(C_6\)] Variance-Reduced Q-Learning under Static and Time-Varying Networks (ACC 2026) [Paper]
[Theme 4] Byzantine-Robust Federated Representation Learning
This project studies how a collection of heterogeneous reinforcement learning agents can collaboratively learn a shared value-function representation when some participating clients are adversarial. Each honest agent interacts with its own Markov decision process under a fixed policy, generating temporally dependent data through a local Markov chain. The agents may have different transition kernels, reward functions, policies, and value functions, so forcing all clients to learn a single common value parameter can introduce a persistent heterogeneity bias.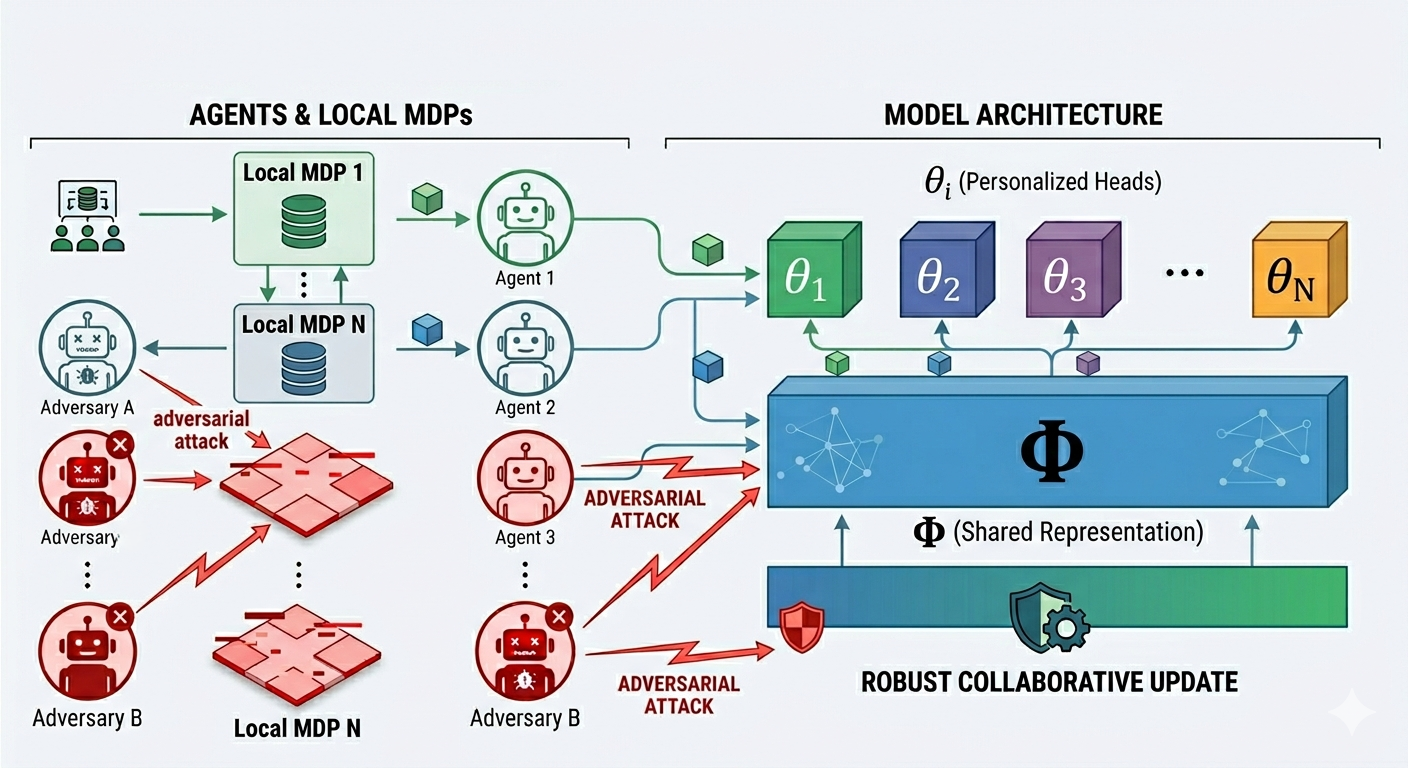
The key idea is to separate what is shared from what is personalized. The value functions of the honest agents are modeled through a common low-dimensional representation, while each agent has its own local parameter vector. Thus, the shared representation captures common structure across agents, while the personalized heads absorb agent-specific MDP heterogeneity.